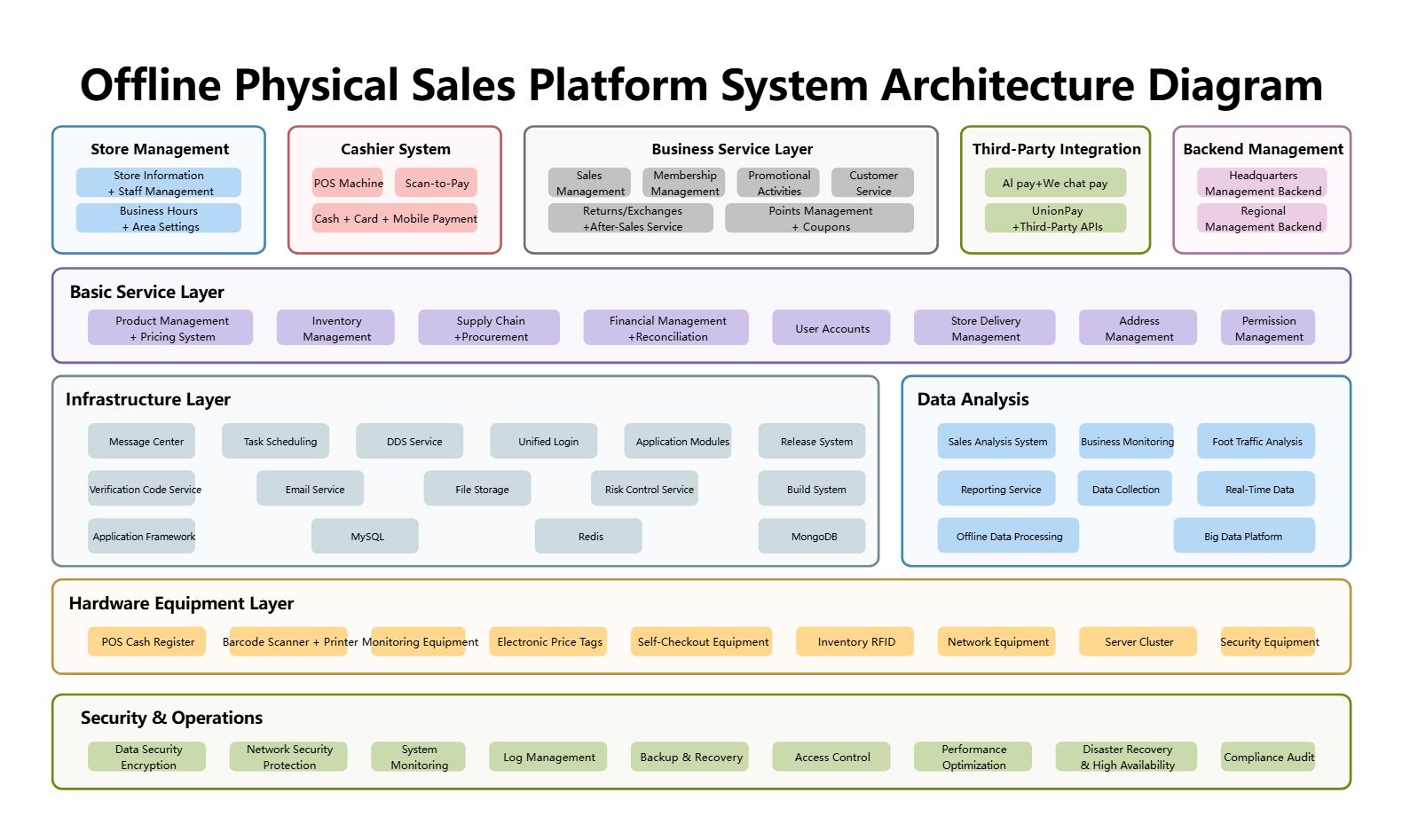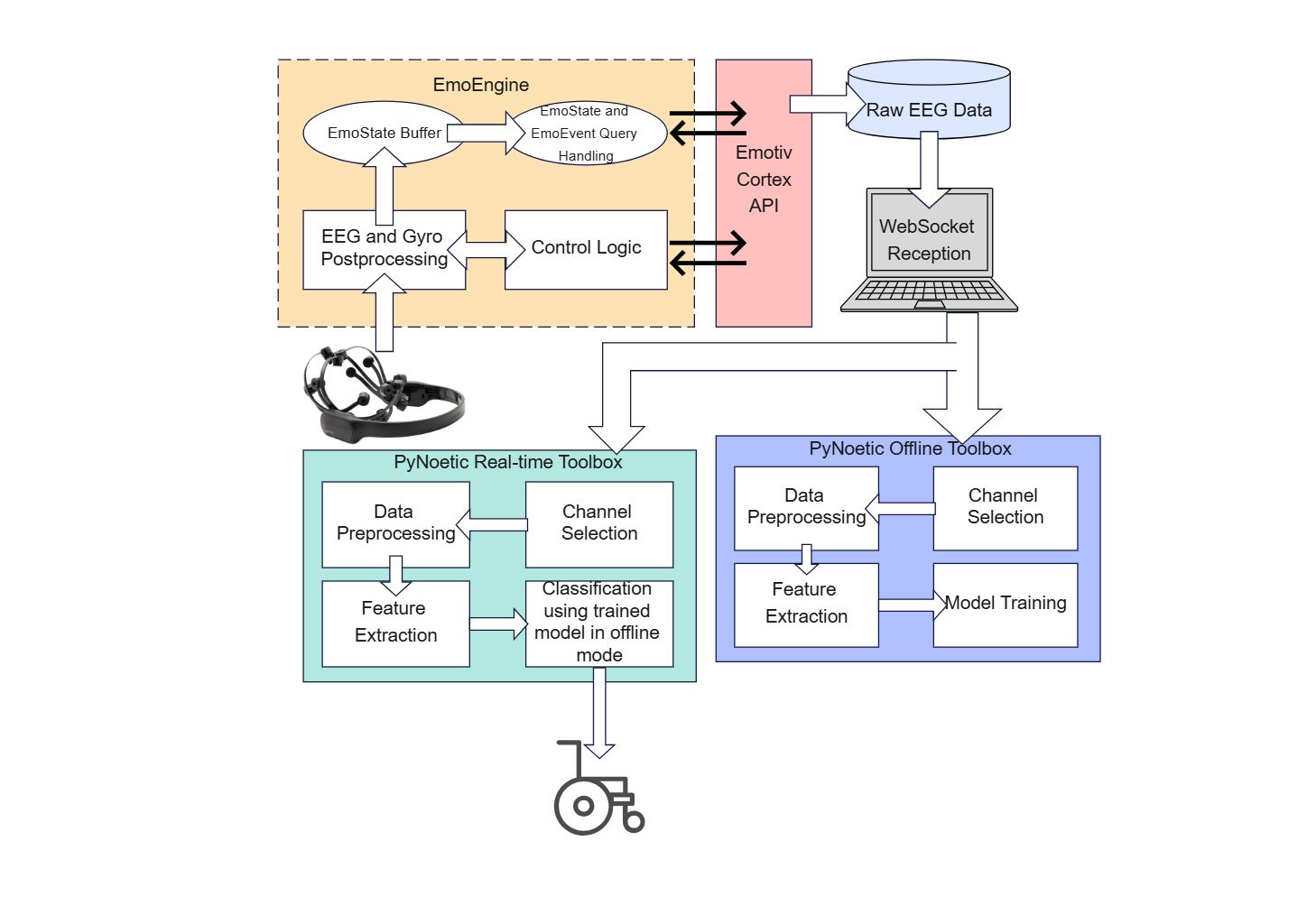
About this Pynoetic System Architecture Diagram
This diagram shows the main structure of a pynoetic system architecture diagram, with the visible layers or blocks separated so each part of the system can be explained more clearly.
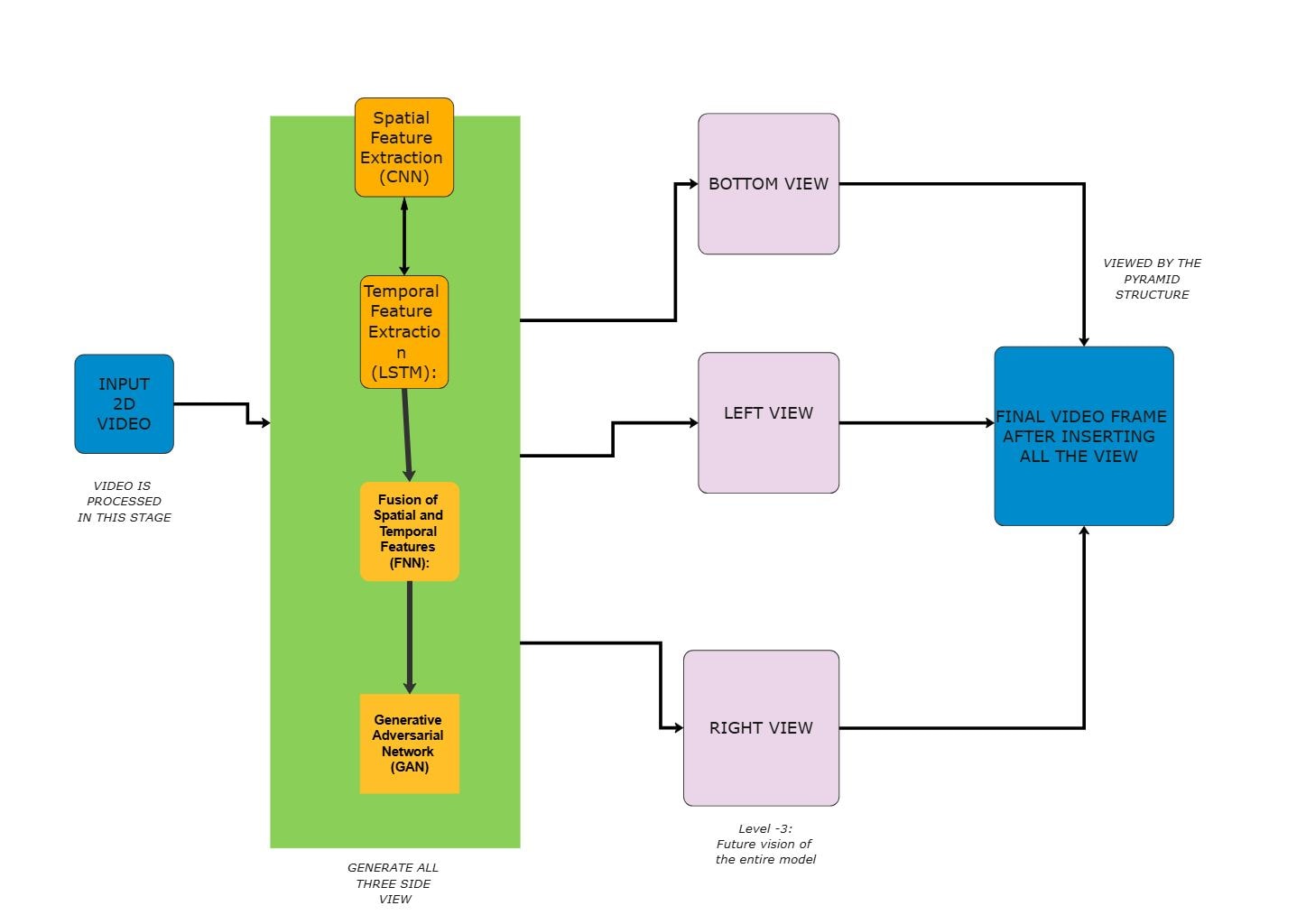
Signal Acquisition
The Signal Acquisition section groups the visible components in this part of the diagram. In this layout, it includes EmoEngine, EmoState Buffer, EmoState and EmoEvent Query Handling, Emotiv Cortex API, which helps define what this block is responsible for in the wider architecture.
- EmoEngine
- EmoState Buffer
- EmoState and EmoEvent Query Handling
- Emotiv Cortex API
- Raw EEG Data
- WebSocket Reception
Preprocessing and Control
The Preprocessing and Control section groups the visible components in this part of the diagram. In this layout, it includes EEG and Gyro Postprocessing, Control Logic, Data Preprocessing, Channel Selection, which helps define what this block is responsible for in the wider architecture.
- EEG and Gyro Postprocessing
- Control Logic
- Data Preprocessing
- Channel Selection
Real-Time Inference
The Real-Time Inference section groups the visible components in this part of the diagram. In this layout, it includes PyNoetic Real-time Toolbox, Feature Extraction, Classification using trained model in offline mode, which helps define what this block is responsible for in the wider architecture.
- PyNoetic Real-time Toolbox
- Feature Extraction
- Classification using trained model in offline mode
Offline Training Workflow
The Offline Training Workflow section groups the visible components in this part of the diagram. In this layout, it includes PyNoetic Offline Toolbox, Data Preprocessing, Channel Selection, Feature Extraction, which helps define what this block is responsible for in the wider architecture.
- PyNoetic Offline Toolbox
- Data Preprocessing
- Channel Selection
- Feature Extraction
- Model Training
FAQs about this Template
-
How do teams document Pynoetic System data architecture?
Teams usually document Pynoetic System data architecture with a diagram that separates ingestion, processing, storage, access, and control layers. This makes it easier to review how information moves through the platform, where data is transformed, and how analytics, governance, reporting, compliance, or downstream systems depend on the same structure. This also makes technical review, stakeholder communication, and future changes easier to manage.
-
What is the difference between data architecture and application architecture?
Data architecture focuses on how information is collected, processed, stored, secured, and consumed, while application architecture describes the broader software structure around it. Data diagrams are more useful when teams need to explain pipelines, databases, warehouses, analytics layers, governance controls, compliance checkpoints, audit visibility, or the movement of records between systems.
-
What should a Pynoetic System data architecture diagram include?
A strong Pynoetic System data architecture diagram should include the main data sources, processing flow, storage layers, and access or reporting points. It should also show where governance, security, integration, transformation, quality checks, or lineage steps connect, so readers can understand the lifecycle of data from entry to operational or analytical use.
-
Can AI generate Pynoetic System data architecture diagrams automatically?
Yes, AI can generate a draft data architecture diagram, but it still needs technical validation. AI can help suggest pipeline stages and system groupings, while engineers should confirm the real data sources, processing order, ownership boundaries, storage design, compliance controls, and support assumptions before using the diagram for planning or review.
-
Which diagram type is best for documenting data pipelines?
A data architecture diagram is usually the best starting point for documenting data pipelines because it shows sources, transformation stages, storage, and consumption paths in one view. Teams may add flowcharts or sequence diagrams later when they need more detail for pipeline execution order, failure handling, alerting, operational troubleshooting, or support ownership.