




AWS data architecture plays a crucial role in data management and analytics for organizations on the cloud. With the rapid growth of data and the increasing adoption of cloud technology, having a well-designed architecture on AWS is essential for organizations to stay competitive. It enables efficient data storage, processing, and analysis, leading to better decision-making and business outcomes.
An AWS data architect is responsible for designing and implementing a scalable and efficient data architecture on AWS.
In this article
Part 1: AWS Data and Its Significance
AWS offers a comprehensive suite of data storage and processing services that cater to the needs of modern organizations. With AWS, businesses can securely store and manage their data in the cloud, leveraging scalable and cost-effective solutions to meet their specific requirements.
AWS provides a range of data storage options, including Amazon Simple Storage Service (S3), Amazon Elastic Block Store (EBS), and Amazon Glacier, each designed to accommodate different types of data and workloads.
Part 2: What Is AWS Data Lake Reference Architecture?
AWS data lake reference architecture provides a blueprint for designing and implementing a scalable, secure, and cost-effective data lake on AWS. The reference architecture encompasses a range of AWS services and best practices that organizations can leverage to build a robust data lake that meets their specific needs.
Part 3: Benefits of Using AWS for Data Lake Architecture
A data lake is a centralized repository that allows organizations to store all their structured and unstructured data at any scale. AWS provides a range of services that support the implementation of data lake architectures, offering numerous benefits to organizations seeking to harness the power of their data.
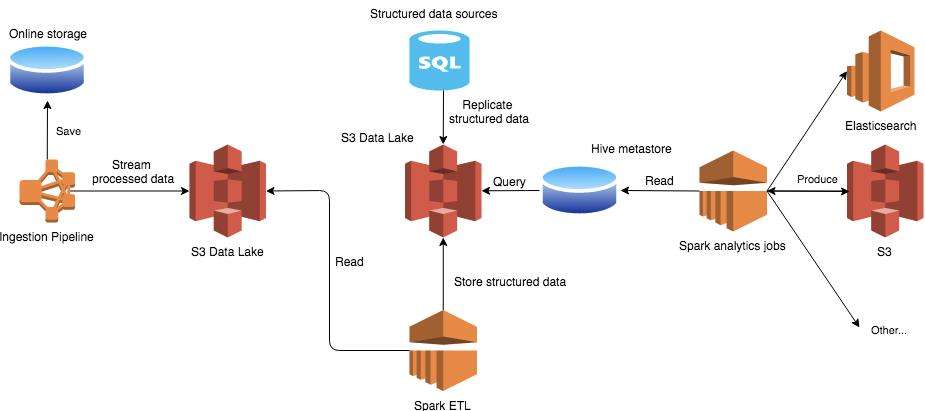
- Scalability: One key benefit of using AWS for data lake architecture is scalability. AWS data lake solutions, such as Amazon S3, are designed to scale seamlessly, allowing organizations to store and process massive volumes of data without the need for upfront investment in infrastructure.
- Flexibility: Another benefit of AWS for data lake architecture is flexibility. AWS offers a variety of data storage and processing services that can be tailored to the specific needs of an organization.
- Cost-effectiveness: AWS data lake architecture offers cost-effectiveness. By leveraging pay-as-you-go pricing models and the ability to optimize resource utilization, organizations can minimize the total cost of ownership associated with managing a data lake.
Part 4: How Do You Utilize AWS for Data Warehouse Architecture?
Data warehouse architecture plays a critical role in enabling organizations to consolidate and analyze data from various sources to support business intelligence and reporting. AWS offers a range of services and best practices for implementing data warehouse architecture, providing organizations with the tools they need to build scalable, high-performance data warehouses.
To utilize AWS data warehouse architecture, organizations can leverage Amazon Redshift, a fully managed data warehouse service that is designed for scalability, performance, and ease of use. Amazon Redshift enables organizations to analyze large volumes of data quickly and cost-effectively, with features such as parallel query execution, automatic compression, and advanced data management capabilities.
Part 5: Make an AWS Data Architecture Diagram with EdrawMax
Data architecture is crucial for any organization as it helps in managing data effectively. To create a comprehensive and visually appealing AWS data architecture diagram, Wondershare EdrawMax offers a variety of customizable templates.
With its easy-to-use drag-and-drop interface, one can easily map out the data flow, relationships, and data integration processes, making it an essential tool for any data-driven organization. Here is how you can make an AWS data architecture diagram with the help of the tool:
Step 1:
To create a Data Architecture Diagram using a Wondershare EdrawMax template, start by logging into your EdrawMax account. Enter your credentials and click on the login button to access the platform.
Step 2:
Once you're logged in, locate the "New Document" button on the top left corner of the interface and click on it. A blank canvas will appear, ready for you to start creating your AWS Data Architecture Diagram.
Step 3:
Next, navigate to the template gallery by clicking on the "Templates" tab in the left sidebar. In the search bar, type "AWS Data Architecture Diagram" and hit enter. EdrawMax will display a range of templates related to data architecture. Choose the one that best suits your needs and click on it to open it.
Step 4:
Now that you have the template open, it's time to customize it according to your requirements. You can change colors, fonts, and styles to match your desired aesthetic.
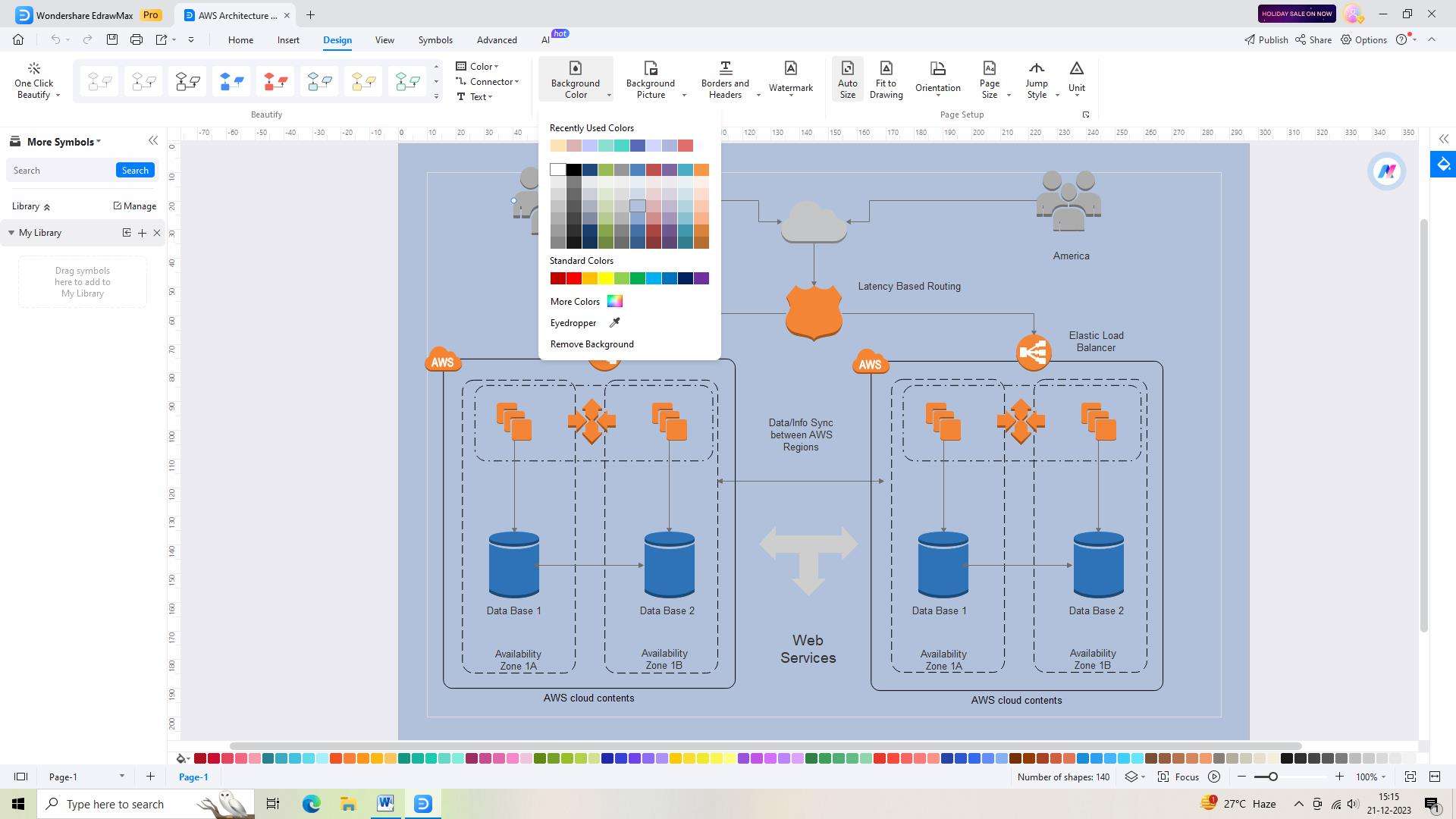
Step 5:
Once you're satisfied with the changes made, it's essential to save your AWS Data Architecture Diagram. Click on the "Save" button located in the top toolbar. Give your diagram a name and choose a location on your computer or cloud storage to save it.
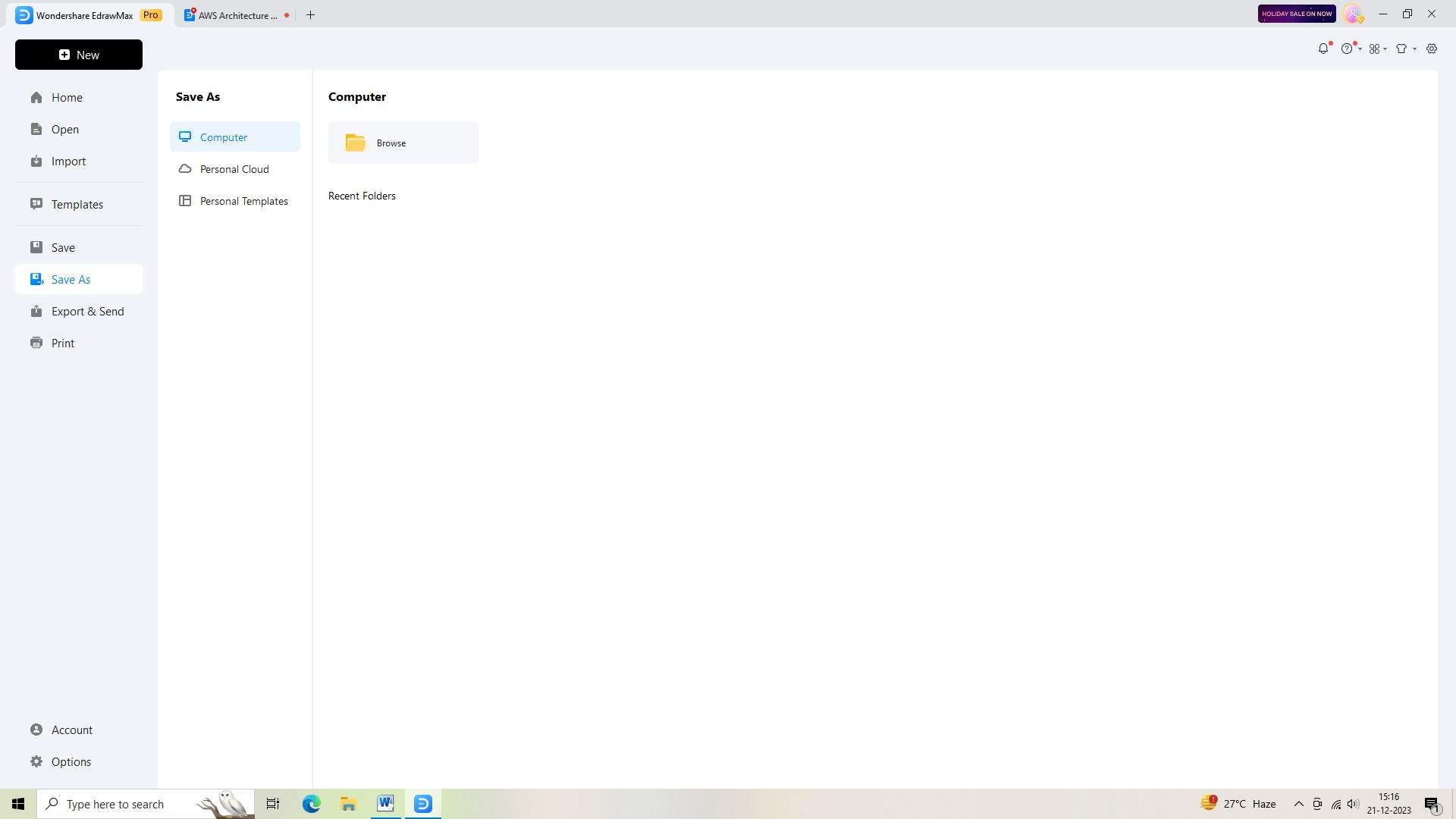
Step 6:
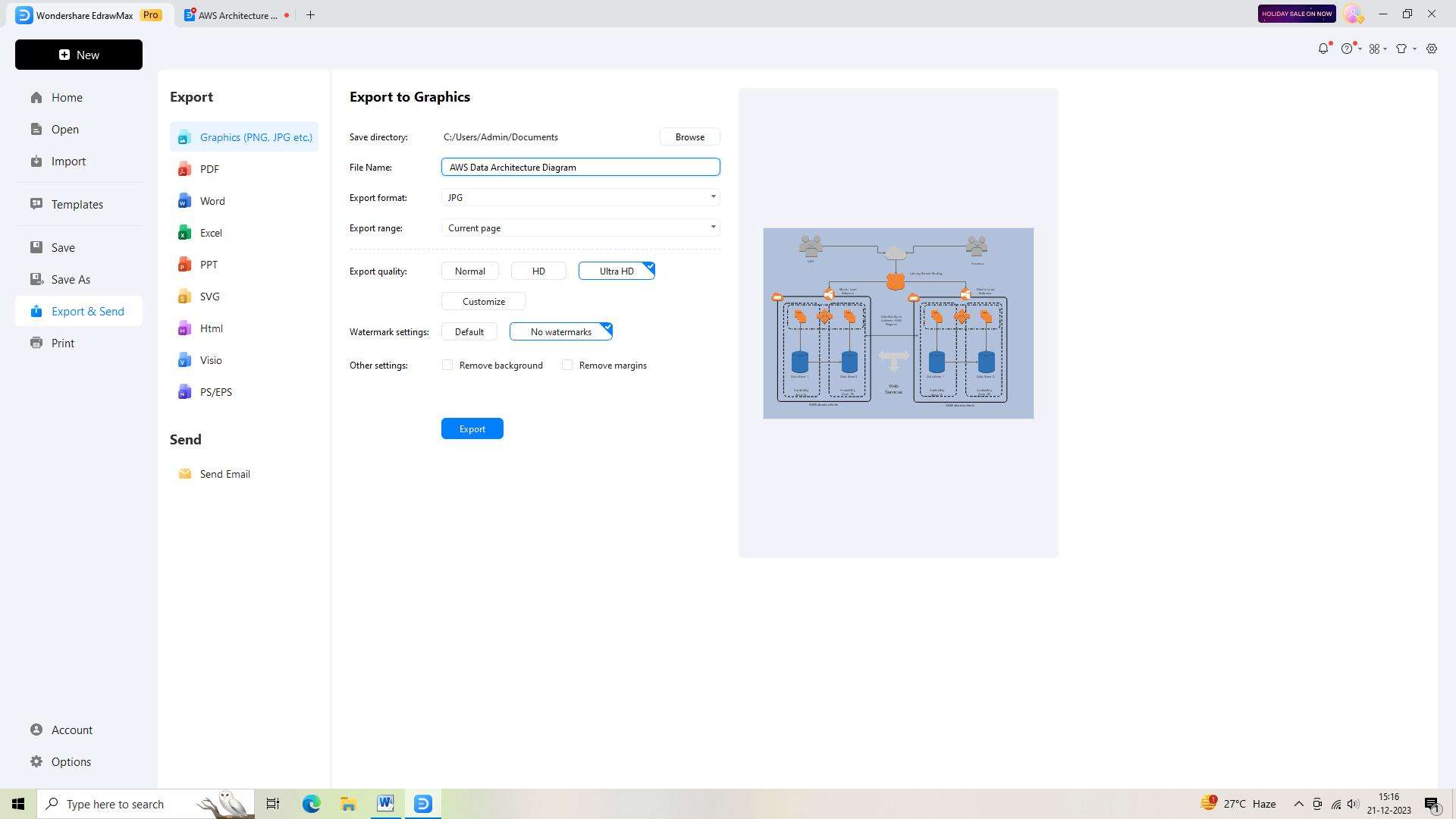
To share or use your AWS Data Architecture Diagram outside of EdrawMax, you'll need to export it. Click on the "Export" button in the top toolbar and choose the desired file format, such as PDF or PNG.
Conclusion
As more and more organizations migrate to the cloud, having a well-designed data architecture on AWS becomes crucial for efficient data management and analytics. Data lake architecture on AWS and AWS Data Warehouse Architecture are some examples of AWS data architecture. A well-designed data architecture on AWS not only ensures efficient data management and analytics but also enables scalability and flexibility for growing business needs.
AI Diagram Generator
Enter your prompt. Upload files if needed. Generate diagrams, charts, or slides instantly.


